Statistics¶
There are many specialized packages for dealing with data analysis and statistical programming. One very important code that you will see in MATH1024, Introduction to Probability and Statistics, is R. A Python package for performing similar analysis of large data sets is pandas. However, simple statistical tasks on simple data sets can be tackled using numpy and scipy.
Getting data in¶
A data file containing the monthly rainfall for Southampton, taken from the Met Office data can be downloaded from this link. We will save that file locally, and then look at the data.
The first few lines of the file are:
[1]:
!head southampton_precip.txt
#Year Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1855 85.6 54.3 61.3 10.1 60.0 43.9 101.0 47.9 88.4 187.5 28.2 55.4
1856 93.5 50.6 36.3 127.3 55.7 40.3 16.5 64.7 67.6 74.5 38.7 87.1
1857 72.3 10.6 54.4 60.7 19.0 38.2 43.7 66.3 93.6 191.4 57.1 25.0
1858 27.0 33.1 22.9 94.1 65.7 14.1 69.6 55.5 75.2 66.2 50.1 116.6
1859 59.6 78.3 49.7 92.4 36.8 45.7 66.6 58.3 135.3 119.8 125.1 127.1
1860 129.2 29.3 59.3 47.6 88.7 205.0 84.7 115.0 99.2 53.2 80.2 127.7
1861 20.7 60.2 76.4 10.2 41.3 100.8 103.5 22.2 78.0 27.7 164.3 53.2
1862 104.0 20.1 124.2 57.5 123.9 53.8 52.8 36.3 29.7 171.8 22.4 72.7
1863 129.4 32.4 38.7 20.5 55.2 94.6 26.4 63.9 98.7 115.3 60.7 64.4
We can use numpy to load this data into a variable, where we can manipulate it. This is not ideal: it will lose the information in the header, and that the first column corresponds to years. However, it is simple to use.
[2]:
import numpy
[3]:
data = numpy.loadtxt('southampton_precip.txt')
[4]:
data
[4]:
array([[ 1855. , 85.6, 54.3, ..., 187.5, 28.2, 55.4],
[ 1856. , 93.5, 50.6, ..., 74.5, 38.7, 87.1],
[ 1857. , 72.3, 10.6, ..., 191.4, 57.1, 25. ],
...,
[ 1997. , 16.4, 112.2, ..., 64.5, 151.4, 100.5],
[ 1998. , 118.5, 9.5, ..., 135.1, 59. , 87.3],
[ 1999. , 129.4, 28.8, ..., 66.8, 49.6, 138.8]])
We see that the first column - the year - has been converted to a floating point number, which is not helpful. However, we can now split the data using standard numpy operations:
[5]:
years = data[:, 0]
rainfall = data[:, 1:]
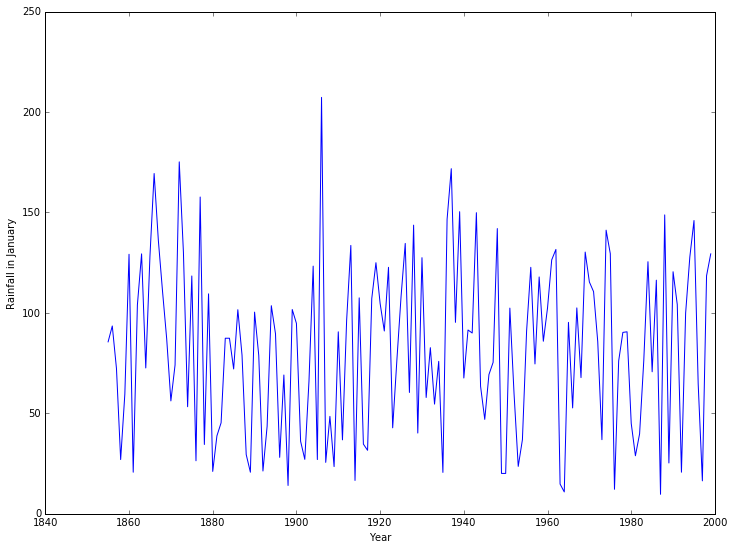
We can now plot, for example, the rainfall in January for all years:
[6]:
%matplotlib inline
from matplotlib import rcParams
rcParams['figure.figsize']=(12,9)
[7]:
from matplotlib import pyplot
[8]:
pyplot.plot(years, rainfall[:,0])
pyplot.xlabel('Year')
pyplot.ylabel('Rainfall in January');
Basic statistical functions¶
numpy contains a number of basic statistical functions, such as min, max and mean. These will act on entire arrays to give the “all time” minimum, maximum, and average rainfall:
[9]:
print("Minimum rainfall: {}".format(rainfall.min()))
print("Maximum rainfall: {}".format(rainfall.max()))
print("Mean rainfall: {}".format(rainfall.mean()))
Minimum rainfall: 0.0
Maximum rainfall: 280.7
Mean rainfall: 67.03591954022988
Of more interest would be either
- the mean (min/max) rainfall in a given month for all years, or
- the mean (min/max) rainfall in a given year for all months.
So the mean rainfall in the first year, 1855, would be
[10]:
print ("Mean rainfall in 1855: {}".format(rainfall[0, :].mean()))
Mean rainfall in 1855: 68.63333333333334
Whilst the mean rainfall in January, averaging over all years, would be
[11]:
print ("Mean rainfall in January: {}".format(rainfall[:, 0].mean()))
Mean rainfall in January: 81.86482758620689
If we wanted to plot the mean rainfall per year, across all years, this would be tedious - there are 145 years of data in the file. Even computing the mean rainfall in each month, across all years, would be bad with 12 months. We could write a loop. However, numpy allows us to apply a function along an axis of the array, which does this is one operation:
[12]:
mean_rainfall_in_month = rainfall.mean(axis=0)
mean_rainfall_per_year = rainfall.mean(axis=1)
The axis argument gives the direction we want to keep - that we do not apply the operation to. For this data set, each row contains a year and each column a month. To find the mean in a given month we want to keep the row information (axis 0) and take the mean over the column. To find the mean in a given year we want to keep the column information (axis 1) and take the mean over the row.
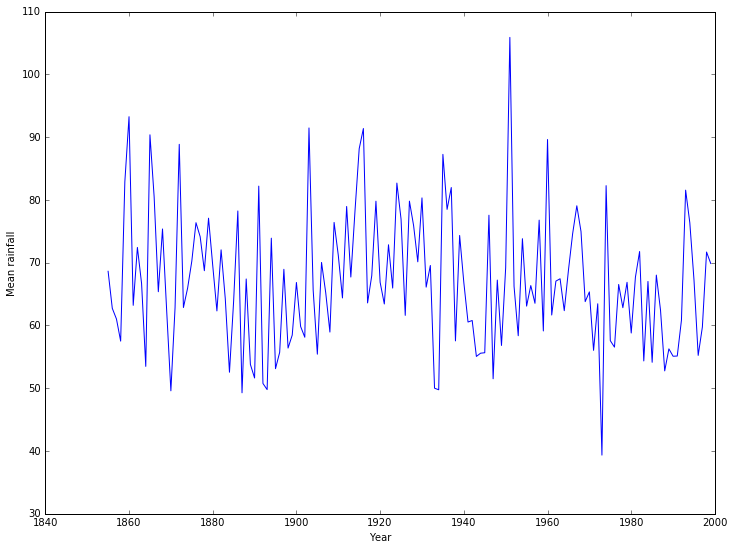
We can now plot how the mean varies with each year.
[13]:
pyplot.plot(years, mean_rainfall_per_year)
pyplot.xlabel('Year')
pyplot.ylabel('Mean rainfall');
We can also compute the standard deviation:
[14]:
std_rainfall_per_year = rainfall.std(axis=1)
We can then add confidence intervals to the plot:
[15]:
pyplot.errorbar(years, mean_rainfall_per_year, yerr = std_rainfall_per_year)
pyplot.xlabel('Year')
pyplot.ylabel('Mean rainfall');
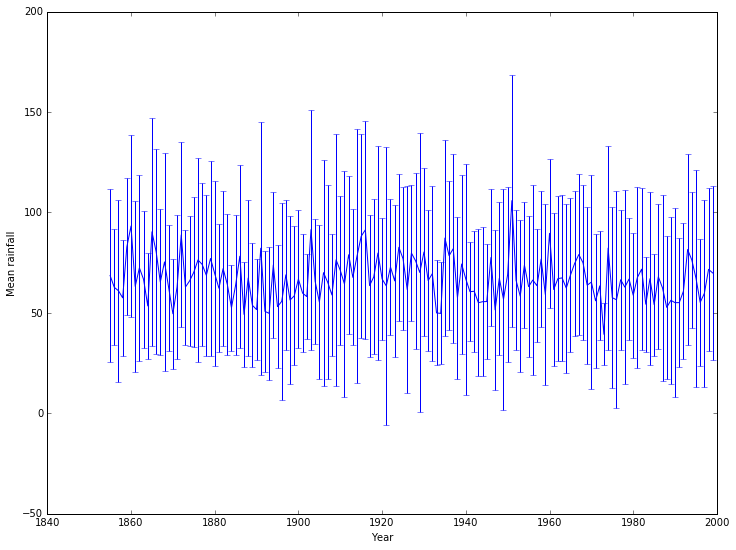
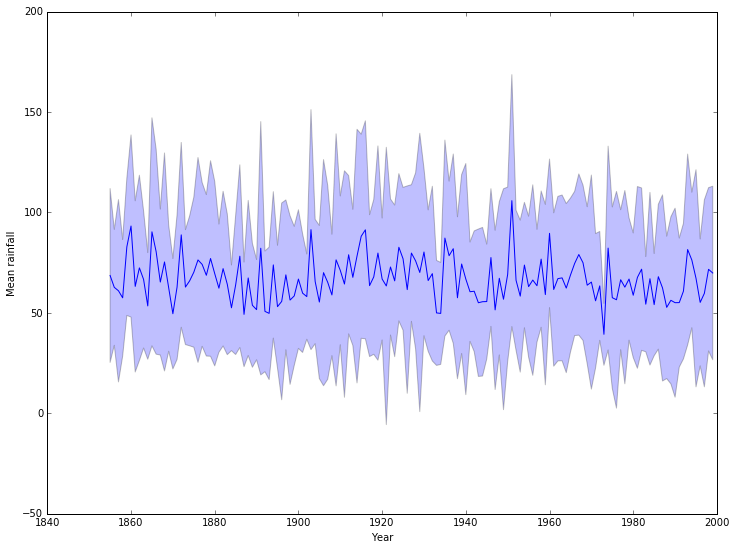
This isn’t particularly pretty or clear: a nicer example would use better packages, but a quick fix uses an alternative matplotlib approach:
[16]:
pyplot.plot(years, mean_rainfall_per_year)
pyplot.fill_between(years, mean_rainfall_per_year - std_rainfall_per_year,
mean_rainfall_per_year + std_rainfall_per_year,
alpha=0.25, color=None)
pyplot.xlabel('Year')
pyplot.ylabel('Mean rainfall');
Categorical data¶
Looking at the means by month, it would be better to give them names rather than numbers. We will also summarize the available information using a boxplot:
[17]:
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
pyplot.boxplot(rainfall, labels=months)
pyplot.xlabel('Month')
pyplot.ylabel('Mean rainfall');
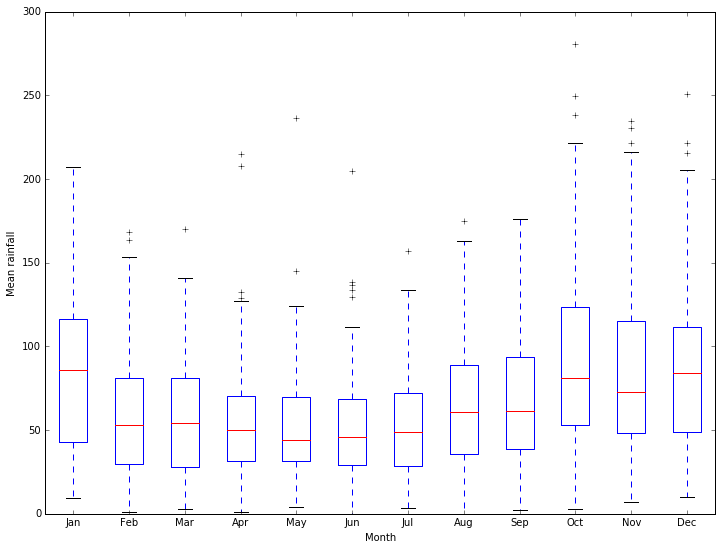
Much better ways of working with categorical data are available through more specialized packages.
Regression¶
We can go beyond the basic statistical functions in numpy and look at other standard tasks. For example, we can look for simple trends in our data with a linear regression. There is a function to compute the linear regression in scipy we can use. We will use this to see if there is a trend in the mean yearly rainfall:
[18]:
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(years, mean_rainfall_per_year)
pyplot.plot(years, mean_rainfall_per_year, 'b-', label='Data')
pyplot.plot(years, intercept + slope*years, 'k-', label='Linear Regression')
pyplot.xlabel('Year')
pyplot.ylabel('Mean rainfall')
pyplot.legend();
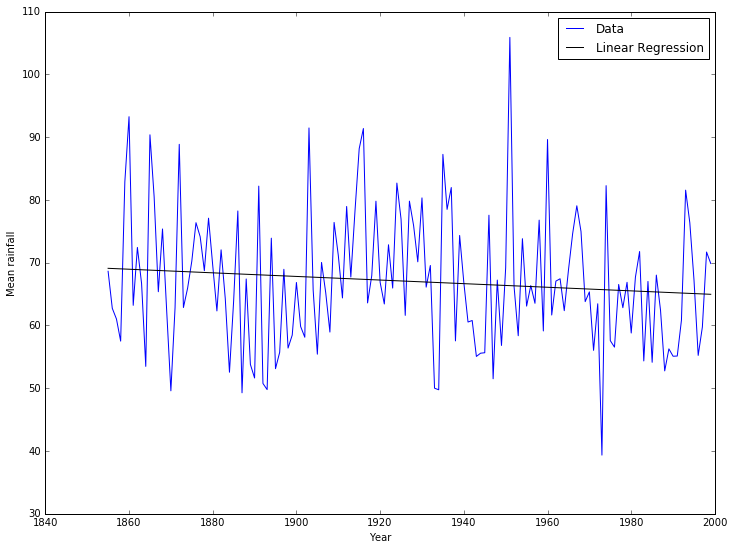
[19]:
print("The change in rainfall (the slope) is {}.".format(slope))
print("However, the error estimate is {}.".format(std_err))
print("The correlation coefficient between rainfall and year"
" is {}.".format(r_value))
print("The probability that the slope is zero is {}.".format(p_value))
The change in rainfall (the slope) is -0.028739338949246847.
However, the error estimate is 0.021587122926201515.
The correlation coefficient between rainfall and year is -0.11064686384415015.
The probability that the slope is zero is 0.18520267346715713.
It looks like there’s a good chance that the slight decrease in mean rainfall with time is a real effect.
Random numbers¶
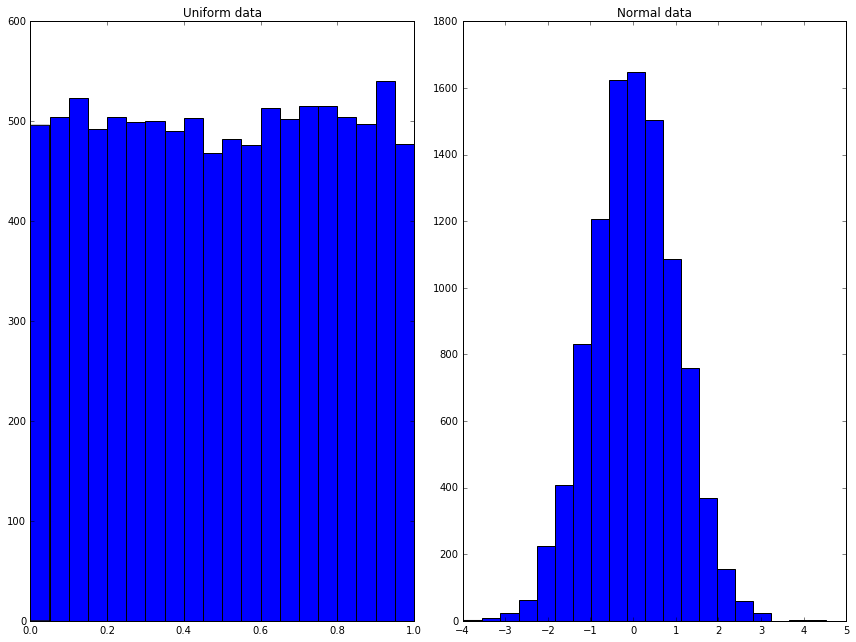
Random processes and random variables may be at the heart of probability and statistics, but computers cannot generate anything “truly” random. Instead they can generate pseudo-random numbers using random number generators (RNGs). Constructing a random number generator is a hard problem and wherever possible you should use a well-tested RNG rather than attempting to write your own.
Python has many ways of generating random numbers. Perhaps the most useful are given by the `numpy.random <http://docs.scipy.org/doc/numpy/reference/routines.random.html>`__ module, which can generate a numpy array filled with random numbers from various distributions. For example:
[20]:
from numpy import random
uniform = random.rand(10000)
normal = random.randn(10000)
fig = pyplot.figure()
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.hist(uniform, 20)
ax1.set_title('Uniform data')
ax2.hist(normal, 20)
ax2.set_title('Normal data')
fig.tight_layout()
fig.show();
/Users/ih3/anaconda/lib/python3.4/site-packages/matplotlib/figure.py:397: UserWarning: matplotlib is currently using a non-GUI backend, so cannot show the figure
"matplotlib is currently using a non-GUI backend, "
More distributions¶
Whilst the standard distributions are given by the convenience functions above, the full documentation of ``numpy.random` <http://docs.scipy.org/doc/numpy/reference/routines.random.html>`__ shows many other distributions available. For example, we can draw  samples from the Beta distribution using the parameters
samples from the Beta distribution using the parameters 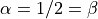 as
as
[21]:
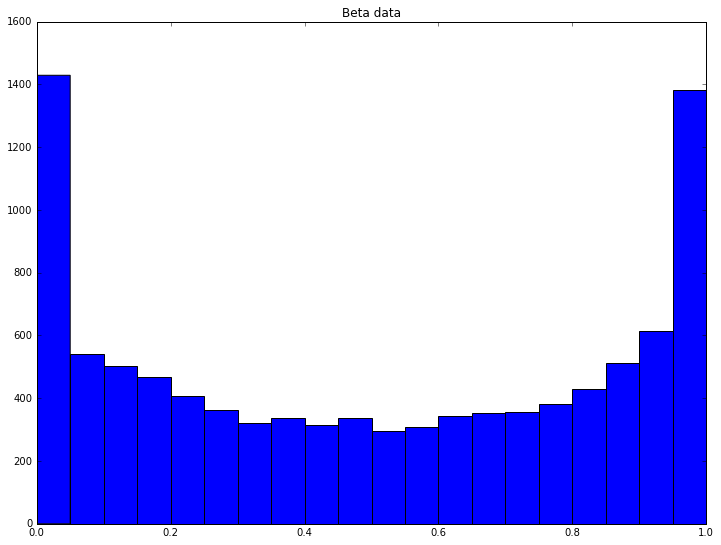
beta_samples = random.beta(0.5, 0.5, 10000)
pyplot.hist(beta_samples, 20)
pyplot.title('Beta data')
pyplot.show();
We can do this 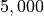 times and compute the mean of each set of samples:
times and compute the mean of each set of samples:
[22]:
n_trials = 5000
beta_means = numpy.zeros((n_trials,))
for trial in range(n_trials):
beta_samples = random.beta(0.5, 0.5, 10000)
beta_means[trial] = numpy.mean(beta_samples)
pyplot.hist(beta_means, 20)
pyplot.title('Mean of Beta trials')
pyplot.show();
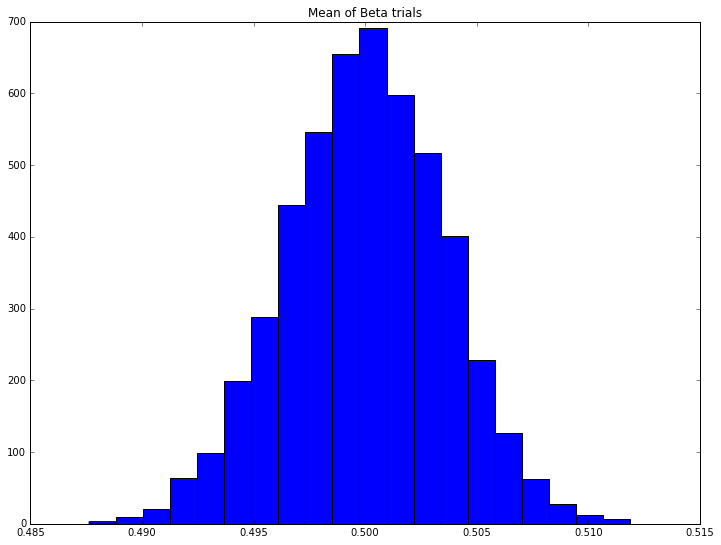
Here we see the Central Limit Theorem in action: the distribution of the means appears to be normal, despite the distribution of any individual trial coming from the Beta distribution, which looks very different.
Exercise: Anscombe’s quartet¶
Four separate datasets are given:
| x | y | x | y | x | y | x | y |
|---|---|---|---|---|---|---|---|
| 10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 |
| 8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 |
| 13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 |
| 9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 |
| 11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 |
| 14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 |
| 6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 |
| 4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 |
| 12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 |
| 7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 |
| 5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 |
Exercise 1¶
Using standard numpy operations, show that each dataset has the same mean and standard deviation, to two decimal places.
Exercise 2¶
Using the standard scipy function, compute the linear regression of each data set and show that the slope and correlation coefficient match to two decimal places.
Exercise 3¶
Plot each dataset. Add the best fit line. Then look at the description of Anscombe’s quartet, and consider in what order the operations in this exercise should have been done.